Note
Go to the end to download the full example code.
SSVEP Decoding
This notebook runs only the data analysis part of experiment.
Look at the notes to see how this can be run on the web with binder or google collab.
All of the additional notes are removed; only the code cells are kept.
Setup
# Some standard pythonic imports
import warnings
warnings.filterwarnings('ignore')
import os,numpy as np,pandas as pd
from collections import OrderedDict
import seaborn as sns
from matplotlib import pyplot as plt
# MNE functions
from mne import Epochs,find_events
from mne.decoding import Vectorizer
# EEG-Notebooks functions
from eegnb.analysis.analysis_utils import load_data
from eegnb.datasets import fetch_dataset
# Scikit-learn and Pyriemann ML functionalities
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.model_selection import cross_val_score, StratifiedShuffleSplit
from pyriemann.estimation import Covariances, ERPCovariances, XdawnCovariances
from pyriemann.spatialfilters import CSP
from pyriemann.tangentspace import TangentSpace
from pyriemann.classification import MDM
Load Data
( See the ssvep load_and_visualize example for further description of this)
eegnb_data_path = os.path.join(os.path.expanduser('~/'),'.eegnb', 'data')
ssvep_data_path = os.path.join(eegnb_data_path, 'visual-SSVEP', 'eegnb_examples')
# If dataset hasn't been downloaded yet, download it
if not os.path.isdir(ssvep_data_path):
fetch_dataset(data_dir=eegnb_data_path, experiment='visual-SSVEP', site='eegnb_examples')
subject = 1
session = 1
raw = load_data(subject, session,
experiment='visual-SSVEP', site='eegnb_examples', device_name='muse2016',
data_dir = eegnb_data_path,
replace_ch_names={'Right AUX': 'POz'})
Loading these files:
/home/runner/.eegnb/data/visual-SSVEP/eegnb_examples/muse2016/subject0001/session001/data_2017-09-14-21.20.04.csv
/home/runner/.eegnb/data/visual-SSVEP/eegnb_examples/muse2016/subject0001/session001/data_2017-09-14-21.29.57.csv
/home/runner/.eegnb/data/visual-SSVEP/eegnb_examples/muse2016/subject0001/session001/data_2017-09-14-21.22.51.csv
/home/runner/.eegnb/data/visual-SSVEP/eegnb_examples/muse2016/subject0001/session001/data_2017-09-14-21.27.36.csv
/home/runner/.eegnb/data/visual-SSVEP/eegnb_examples/muse2016/subject0001/session001/data_2017-09-14-21.32.15.csv
/home/runner/.eegnb/data/visual-SSVEP/eegnb_examples/muse2016/subject0001/session001/data_2017-09-14-21.25.17.csv
['TP9', 'AF7', 'AF8', 'TP10', 'Right AUX', 'stim']
['TP9', 'AF7', 'AF8', 'TP10', 'POz', 'stim']
Creating RawArray with float64 data, n_channels=6, n_times=30732
Range : 0 ... 30731 = 0.000 ... 120.043 secs
Ready.
['TP9', 'AF7', 'AF8', 'TP10', 'Right AUX', 'stim']
['TP9', 'AF7', 'AF8', 'TP10', 'POz', 'stim']
Creating RawArray with float64 data, n_channels=6, n_times=30732
Range : 0 ... 30731 = 0.000 ... 120.043 secs
Ready.
['TP9', 'AF7', 'AF8', 'TP10', 'Right AUX', 'stim']
['TP9', 'AF7', 'AF8', 'TP10', 'POz', 'stim']
Creating RawArray with float64 data, n_channels=6, n_times=30732
Range : 0 ... 30731 = 0.000 ... 120.043 secs
Ready.
['TP9', 'AF7', 'AF8', 'TP10', 'Right AUX', 'stim']
['TP9', 'AF7', 'AF8', 'TP10', 'POz', 'stim']
Creating RawArray with float64 data, n_channels=6, n_times=30720
Range : 0 ... 30719 = 0.000 ... 119.996 secs
Ready.
['TP9', 'AF7', 'AF8', 'TP10', 'Right AUX', 'stim']
['TP9', 'AF7', 'AF8', 'TP10', 'POz', 'stim']
Creating RawArray with float64 data, n_channels=6, n_times=30732
Range : 0 ... 30731 = 0.000 ... 120.043 secs
Ready.
['TP9', 'AF7', 'AF8', 'TP10', 'Right AUX', 'stim']
['TP9', 'AF7', 'AF8', 'TP10', 'POz', 'stim']
Creating RawArray with float64 data, n_channels=6, n_times=30720
Range : 0 ... 30719 = 0.000 ... 119.996 secs
Ready.
Marking edge at 30732 samples (maps to 120.047 sec)
Marking edge at 61464 samples (maps to 240.094 sec)
Marking edge at 92196 samples (maps to 360.141 sec)
Marking edge at 122916 samples (maps to 480.141 sec)
Marking edge at 153648 samples (maps to 600.188 sec)
Epoching
# Next, we will chunk (epoch) the data into segments representing the data 100ms before to 800ms after each stimulus.
# Note: we will not reject epochs here because the amplitude of the SSVEP at POz is so large it is difficult to separate from eye blinks
events = find_events(raw)
event_id = {'30 Hz': 1, '20 Hz': 2}
epochs = Epochs(raw, events=events, event_id=event_id,
tmin=-0.5, tmax=4, baseline=None, preload=True,
verbose=False, picks=[0, 1, 2, 3, 4])
print('sample drop %: ', (1 - len(epochs.events)/len(events)) * 100)
Finding events on: stim
197 events found on stim channel stim
Event IDs: [1 2]
sample drop %: 2.538071065989844
Decoding
# We can use a filter bank approach on the original 4 Muse electrodes (to see how the headband alone without external electrodes could be used to classify SSVEP):
# - Apply bandpass filters around both stimulation frequencies
# - Concatenate bandpass-filtered channels
# - Extract epochs (from 1 to 3 s after stimulus onset, to avoid classifying the ERP)
# - Apply common classification pipelines
# Bandpass filter the raw data
muse_raw = raw.drop_channels(['POz'])
raw_filt_30Hz = muse_raw.copy().filter(25, 35, method='iir')
raw_filt_20Hz = muse_raw.copy().filter(15, 25, method='iir')
raw_filt_30Hz.rename_channels(lambda x: x + '_30Hz')
raw_filt_20Hz.rename_channels(lambda x: x + '_20Hz')
# Concatenate with the bandpass filtered channels
raw_all = raw_filt_30Hz.add_channels([raw_filt_20Hz],
force_update_info=True)
# Extract epochs
events = find_events(raw_all)
event_id = {'30 Hz': 1, '20 Hz': 2}
epochs_all = Epochs(raw_all, events=events, event_id=event_id,
tmin=1, tmax=3, baseline=None,
reject={'eeg': 100e-6}, preload=True, verbose=False,)
epochs_all.pick_types(eeg=True)
X = epochs_all.get_data() * 1e6
times = epochs.times
y = epochs_all.events[:, -1]
Filtering raw data in 6 contiguous segments
Setting up band-pass filter from 25 - 35 Hz
IIR filter parameters
---------------------
Butterworth bandpass zero-phase (two-pass forward and reverse) non-causal filter:
- Filter order 16 (effective, after forward-backward)
- Cutoffs at 25.00, 35.00 Hz: -6.02, -6.02 dB
Filtering raw data in 6 contiguous segments
Setting up band-pass filter from 15 - 25 Hz
IIR filter parameters
---------------------
Butterworth bandpass zero-phase (two-pass forward and reverse) non-causal filter:
- Filter order 16 (effective, after forward-backward)
- Cutoffs at 15.00, 25.00 Hz: -6.02, -6.02 dB
Finding events on: stim_30Hz, stim_20Hz
197 events found on stim channel stim_30Hz
Event IDs: [1 2]
197 events found on stim channel stim_20Hz
Event IDs: [1 2]
NOTE: pick_types() is a legacy function. New code should use inst.pick(...).
Decoding
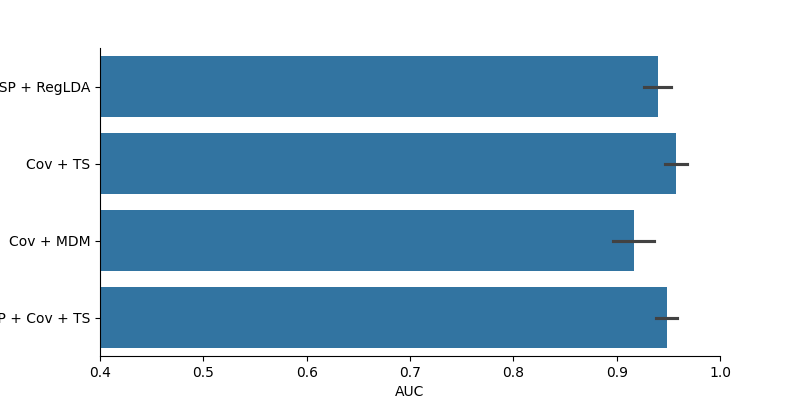
# Next, we will use 4 different machine learning pipelines to classify the SSVEP based on the data we collected. The
# - CSP + RegLDA : Common Spatial Patterns + Regularized Linear Discriminat Analysis. This is a very common EEG analysis pipeline.
# - Cov + TS : Covariance + Tangent space mapping. One of the most reliable Riemannian geometry-based pipelines.
# - Cov + MDM: Covariance + MDM. A very simple, yet effective (for low channel count), Riemannian geometry classifier.
# - CSP + Cov + TS: Common Spatial Patterns + Covariance + Tangent spacem mapping. Riemannian pipeline with the standard CSP procedure beforehand
# Evaluation is done through cross-validation, with area-under-the-curve (AUC) as metric (AUC is probably the best metric for binary and unbalanced classification problem)
# Note: because we're doing machine learning here, the following cell may take a while to complete
clfs = OrderedDict()
clfs['CSP + RegLDA'] = make_pipeline(Covariances(), CSP(4), LDA(shrinkage='auto', solver='eigen'))
clfs['Cov + TS'] = make_pipeline(Covariances(), TangentSpace(), LogisticRegression())
clfs['Cov + MDM'] = make_pipeline(Covariances(), MDM())
clfs['CSP + Cov + TS'] = make_pipeline(Covariances(), CSP(4, log=False), TangentSpace(), LogisticRegression())
# define cross validation
cv = StratifiedShuffleSplit(n_splits=20, test_size=0.25,
random_state=42)
# run cross validation for each pipeline
auc = []
methods = []
for m in clfs:
print(m)
try:
res = cross_val_score(clfs[m], X, y==2, scoring='roc_auc',cv=cv, n_jobs=-1)
auc.extend(res)
methods.extend([m]*len(res))
except:
pass
results = pd.DataFrame(data=auc, columns=['AUC'])
results['Method'] = methods
fig = plt.figure(figsize=(8, 4))
sns.barplot(data=results, x='AUC', y='Method')
plt.xlim(0.4, 1)
sns.despine()
CSP + RegLDA
Cov + TS
Cov + MDM
CSP + Cov + TS
Total running time of the script: (0 minutes 1.308 seconds)