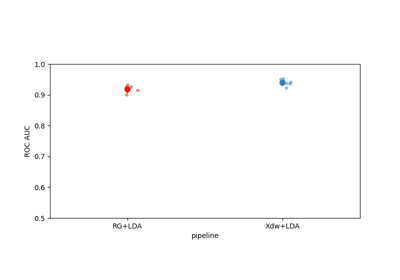
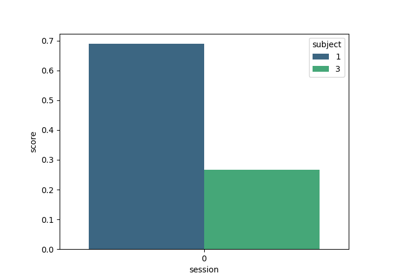
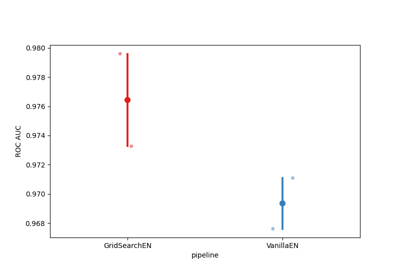
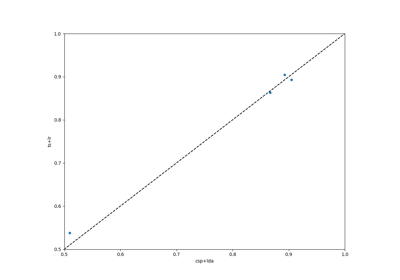
moabb.evaluations.WithinSessionEvaluation#
- class moabb.evaluations.WithinSessionEvaluation(n_perms: Optional[Union[int, list, tuple, ndarray]] = None, data_size: Optional[dict] = None, **kwargs)[source]#
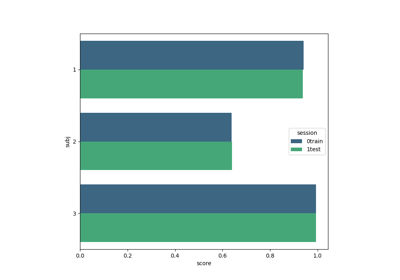
Performance evaluation within session (k-fold cross-validation)
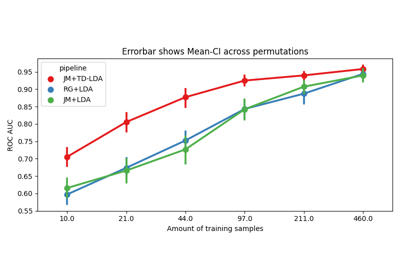
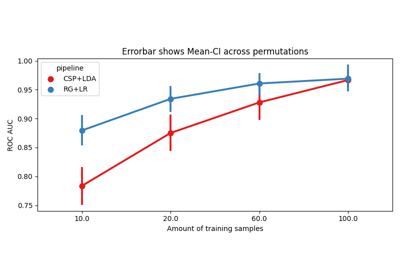
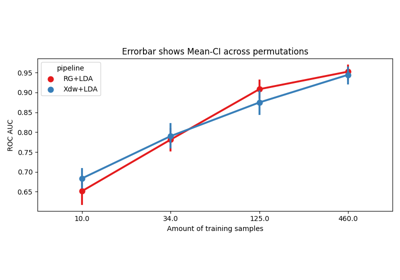
Within-session evaluation uses k-fold cross_validation to determine train and test sets on separate session for each subject, it is possible to estimate the performance on a subset of training examples to obtain learning curves.
- Parameters
n_perms – Number of permutations to perform. If an array is passed it has to be equal in size to the data_size array. Values in this array must be monotonically decreasing (performing more permutations for more data is not useful to reduce standard error of the mean). Default: None
data_size – If None is passed, it performs conventional WithinSession evaluation. Contains the policy to pick the datasizes to evaluate, as well as the actual values. The dict has the key ‘policy’ with either ‘ratio’ or ‘per_class’, and the key ‘value’ with the actual values as an numpy array. This array should be sorted, such that values in data_size are strictly monotonically increasing. Default: None
paradigm (Paradigm instance) – The paradigm to use.
datasets (List of Dataset instance) – The list of dataset to run the evaluation. If none, the list of compatible dataset will be retrieved from the paradigm instance.
random_state (int, RandomState instance, default=None) – If not None, can guarantee same seed for shuffling examples.
n_jobs (int, default=1) – Number of jobs for fitting of pipeline.
overwrite (bool, default=False) – If true, overwrite the results.
error_score ("raise" or numeric, default="raise") – Value to assign to the score if an error occurs in estimator fitting. If set to ‘raise’, the error is raised.
suffix (str) – Suffix for the results file.
hdf5_path (str) – Specific path for storing the results and models.
additional_columns (None) – Adding information to results.
return_epochs (bool, default=False) – use MNE epoch to train pipelines.
return_raws (bool, default=False) – use MNE raw to train pipelines.
mne_labels (bool, default=False) – if returning MNE epoch, use original dataset label if True
- evaluate(dataset, pipelines, param_grid, process_pipeline, postprocess_pipeline=None)[source]#
Evaluate results on a single dataset.
This method return a generator. each results item is a dict with the following conversion:
res = {'time': Duration of the training , 'dataset': dataset id, 'subject': subject id, 'session': session id, 'score': score, 'n_samples': number of training examples, 'n_channels': number of channel, 'pipeline': pipeline name}
- is_valid(dataset)[source]#
Verify the dataset is compatible with evaluation.
This method is called to verify dataset given in the constructor are compatible with the evaluation context.
This method should return false if the dataset does not match the evaluation. This is for example the case if the dataset does not contain enough session for a cross-session eval.
- Parameters
dataset (dataset instance) – The dataset to verify.